My NEXRAD JavaScript libraries have been almost 15 years in the making. And they didn’t start with me plotting my own images.
In the early 2000s websites didn’t have rich, interactive interfaces with dynamically loaded data. Most people point to Gmail as the beginning of these type of AJAX web sites, as they were called at the time back in 2004. Although other web sites did dynamic loading and played other tricks with JavaScript and iframes to achieve similar interfaces.
Weather websites at the time typically had a static image showing the radar, or maybe an animated GIF. This was great. You could see the current radar without having to wait for the 5pm news or for 8 minutes after on The Weather Channel. But for someone who was interested in weather this was still lacking.
Screen Scraping
My first foray into this was through a technique called screen scraping. On my web server I would run a PHP script every few minutes that would check my two favorite radar images at the time: Accuweather and Wunderground. That script would determine if a new image was present and store it to my server. It would keep a total of 5 or 10 images expiring the oldest when a new one arrived.
The web page associated with it would let you view either set of images as an animation by changing out the src attribute on an image tag. This method had it’s drawbacks that have all been addressed in subsequent updates.
Some drawbacks were that images weren’t pre-loaded. On a dial up modem, not uncommon at the time, it might take 3 or 4 times through the loop before all of the images loaded.
Improving the interface
The first two changes implemented allowed for changing the frame rate and and manual forward/back control of the images. Specifically, forward and backward control was accomplished by using the mouse’s scroll wheel. Later when touch screens became prevalent, dragging across the image was added as another way to control this.
This easy manual control via the scroll wheel is something that I have always felt was lacking, and is still, in any radar viewer that I’ve used. For me, this control is critical as an amateur weather enthusiast to be able to follow the storm’s track and watch it’s development.
Next I began pre-loading images. Initially this was done inside of a hidden div, although the method has changed over time. This meant that, especially on a slower connection, that the second and later frames might already be loaded when the animation reached them.
This interface at this point was nice, but if you left it open for several minutes you’d have to manually refresh to see if there were any updates. My initial fix for this was to have JavaScript automatically reload the page every few minutes. But then it got a lot better.
AJAX
In 2009 or 2010 I began learning about Asynchronous Javascript and XML (AJAX). This allowed me to make several changes to the frontend, and supporting changes to the backend. I was now able to load just a “shell” of a page and use an AJAX call to get a list of images from the server to load. This made it very easy to check for a new list every minute without reloading the page.
It also allowed for switching between the Wunderground and Accuweather image sets without reloading the page. And as the image sets grew to include TDWR, satellite, velocity and other regional and national images this became very helpful.
It was around this time as well that I began time stamping images. Or more specifically I would log metadata about the images to a database that included the time I downloaded the image. This was a reasonable estimate of the radar’s time. But it began to make a problem clear. Several of my image sets would occasionally get out of order. I never did sort out exactly why, and it didn’t happen on the source web sites. My suspicion was issues with caching at CDNs or connecting to a different CDN server on subsequent calls that was slightly out of date. This order-of-images problem lived on for almost 10 years.
Jquery
The backend at this time continued to run on PHP. But around 2015 I started experimenting with Jquery and found that it was a much better way to handle all of the interactivity that I had added to the web page. I recall having so much code specific to Firefox, Chrome and at one point even IE and Jquery did away with this. It also integrated some really simple and helpful transition animations that very much helped show the process flow through the web site.
Jquery was a very nice tool at the time to deal with different browsers but by 2021 it was just about unnecessary. The remaining major players in the browser world had all begun following standards to a much better extent than in 2005 when I started this project. So at this time I refactored the code in two ways: removing Jquery in favor of new standard javascript methods and modularizing the code for easier maintainability.

My Own Images
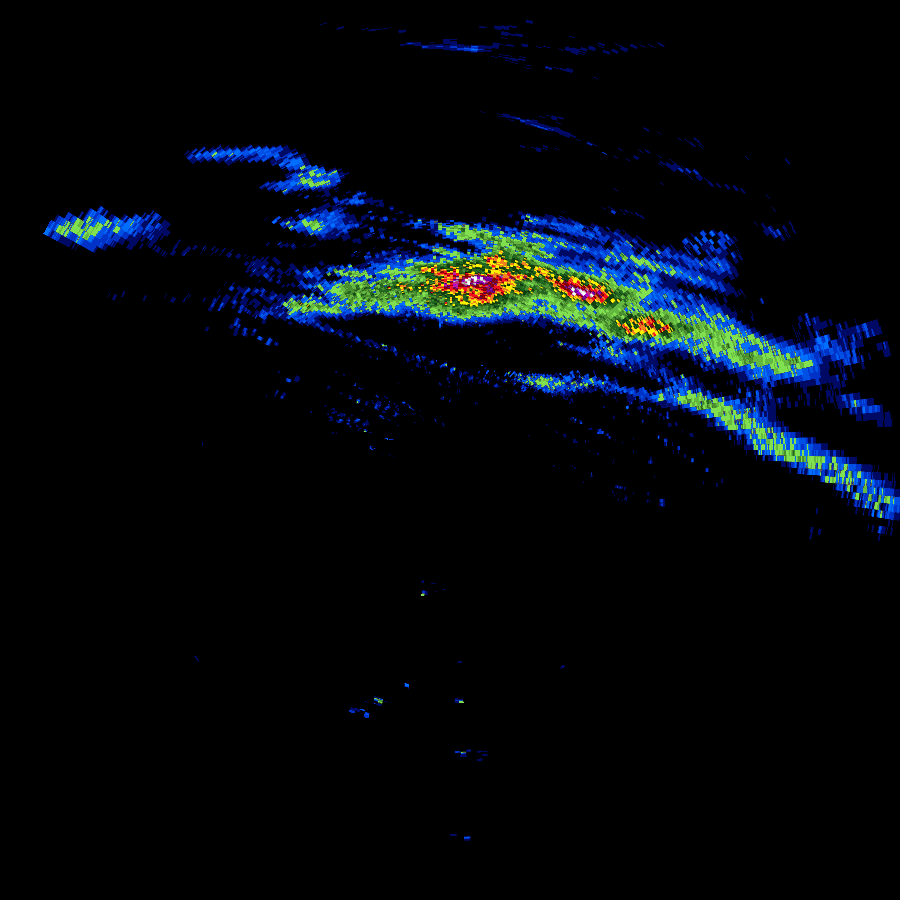
In 2018, while I was out of town for work and browsing the web aimlessly while stuck in a hotel room I came across a Javascript tool for plotting NEXRAD data. It worked, but it was incomplete with regards to modern compression methods used in the current NEXRAD network. I then set out to figure out where to get radar data and just happened to find that AWS S3 was now hosting both archival NEXRAD data as well as “live” data.
The journey here took a lot of effort. I’ll list some of the problems that had to be overcome:
- The bzip format used in current radar products was not standard. There were headers interspersed with chunks of bzip data. The headers were not well defined but I eventually was able to sort them out and wrangle a nodejs bzip library to work on this data.
- The data could be presented in an older format or the new dual-pol/hi-res format. These needed separate handling at the appropriate places to parse the data successfully. Separately, the plotting tool needed to understand the two types to be able to correctly show the data.
- Plotting was slow, initially. A lot of work was done to speed up the plotting process. On a day with some storms, plotting went from 10s originally down to about 2s.
- “Live” data, called chunks, took extra effort to process. A single image may come in as 3 or 6 chunks. I had to study a lot of raw radar data to determine whether to trigger on the 3rd or 6th chunk, and if there was another lowest-elevation scan at some other chunk.
I enjoyed the challenge of making all of this work and it solved the problem of out-of-order images that the screen-scraping method occasionally produced.
You can read more about the NEXRAD tools for JavaScript
Serverless
After I had updated the libraries to deal with the new data formats I had to find a way to run these. Previously I had used PHP on my web server that also hosted wordpress. But the new libraries ran on nodejs. This is when I discovered Lambda and it’s ability to run a one-off function with code that I supplied.
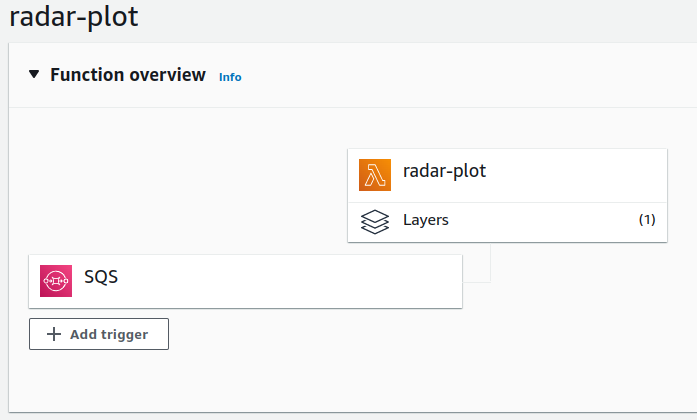
So I set about implementing the library in a way that a lambda function could handle, and it was very capable of plotting this data and storing it to S3. Then other metadata and tasks were adapted to the Lambda environment. The final stack looks something like this:
- An S3 triggered Lambda that reads the first chunk in the set of chunks as they arrive and determines what chunks should be decoded. When those other chunks arrive it then triggers the next process.
- A plot worker receives the “interesting” chunk numbers from the previous function, downloads all of the data for each chunk, plots it and stores it to S3. The plotting consists of reflectivity, velocity at various resolutions and crops.
- The plot worker sends a command to a third lambda function that writes metadata to the database for retrieval by the fronted.
- A separate backend tool that monitors the api.weather.gov for current severe thunderstorm and tornado warnings and stores these to a database in a format that is practical for displaying on the radar map.
- A frontend “list” api that can return a list of current images for a selected radar site, and that can list all current warnings for the current site.
The frontend queries the API for the list of images and warnings, loads the images from S3 and draws the warnings on the image.
Maps
Radar images by themselves are not hugely helpful. You need some context to view them within. Typically road, state and county maps are shown over the radar plot. I used Open Street Map to provide major highways, county and state borders as a base-image for my radar plots. I downloaded the relevant data and used my own nodejs tool to draw these base maps from the data.
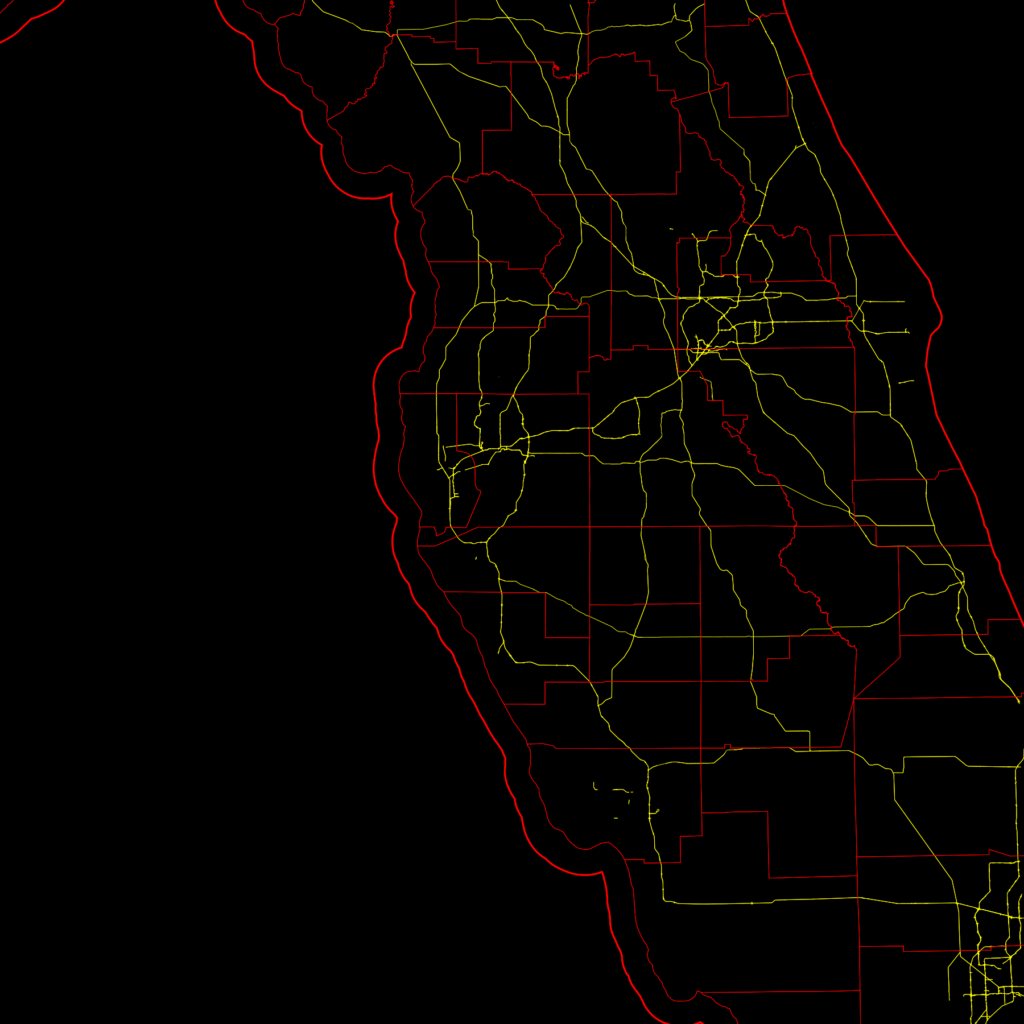
Conclusion
I hope you have enjoyed this journey and would like to see the resulting web site. However I am keeping that site private. There are two reasons for this. One historical and one is cost. Historically, during the screen-scraping days I am sure there were copyright issues with me copying and re-displaying radar images from other web sites. So I kept the site private.
Today, the images are not copyrighted. In fact, any data produced by an agency of the United States Government can not be copyrighted. But there is now a non-zero cost with producing the images. For me to plot the handful of radars around my location, it’s reasonable. But if I were to open the site to the public I would need to plot every radar site. And I’ve calculated this at $150-200 per month which is well outside of what I could pay for out of pocket.
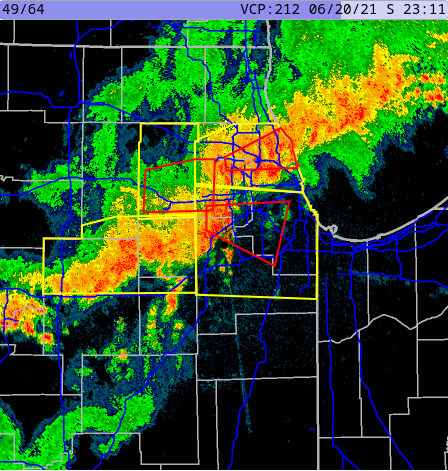
It’s unfortunate, but I’m still very happy with my own results. And I do give my own web site a lot of traffic especially on days when there’s significant weather in my area.